
DOI 10.24411/2658-3569-2019-14044
Методы кластеризации и классификации математического аппарата в обеспечении финансовой политики государства
Methods of clustering and classification of mathematical apparatus
Ибрагимова Элина Саламбековна, ФГБОУ ВО «Чеченский государственный университет», ассистент кафедры финансов и кредита
Аннотация: Задача классификации – формализованная задача, содержащая множество объектов (ситуаций), разделенных определенным образом на классы. Задано конечное множество объектов, для которых известно, к каким классам они относятся. Это множество называется выборкой. К какому классу относятся другие объекты неизвестно. Необходимо построить такой алгоритм, который будет способен классифицировать произвольный объект из исходного множества.
Классифицировать объект – означает, указать номер (или название) класса, к которому относится данный объект.
Классификация объекта – номер или наименование класса, выдаваемый алгоритмом классификации в результате его применения к данному конкретному объекту.
В математической статистике задачи классификации называются также задачами дискретного анализа. В машинном обучении задача классификации решается, как правило, с помощью методов искусственной нейронной сети при постановке эксперимента в виде обучения с учителем.
Существуют также другие способы постановки эксперимента – обучение без учителя, но они используются для решения другой задачи – кластеризации или таксономии. В этих задачах разделение объектов обучающей выборки на классы не задается, и требуется классифицировать объекты только на основе их сходства.
Summary: A classification problem is a formalized problem that contains a set of objects (situations) that are divided into classes in a certain way. Given a finite set of objects for which it is known to which classes they belong. This set is called a sample. It is not known what class the other objects belong to. It is necessary to build an algorithm that will be able to classify an arbitrary object from the original set.
Classify an object-means to specify the number (or name) of the class to which the object belongs.
Object classification – the number or name of the class issued by the classification algorithm as a result of its application to this particular object.
In mathematical statistics, classification problems are also called discrete analysis problems. In machine learning, the classification problem is solved, as a rule, with the help of artificial neural network methods when setting up an experiment in the form of training with a teacher.
There are also other ways of setting up an experiment-learning without a teacher, but they are used to solve another problem-clustering or taxonomy. In these tasks, you do not specify the division of training sample objects into classes, and you want to classify objects only based on their similarity.
Ключевые слова: математическая статистика, объект, классификация, алгоритм, задача.
Keywords: mathematical statistics, object, classification, algorithm, problem.
В некоторых прикладных областях, и даже в самой математической статистике, через близость задач часто не отличают задачи кластеризации от задачи классификации.
Некоторые алгоритмы для решения задач классификации комбинируют обучение с учителем и обучение без учителя, например, одна из версий нейронных сетей Кохонена – Сети векторного квантования, обучаемые способом обучения с учителем.
Пусть X – множество описаний объектов, Y– множество номеров (или наименований) классов. Существует неизвестная целевая зависимость – отображение y`:X→Y, значения которой известны только на элементах конечной обучающей выборки
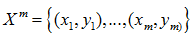
нужно построить алгоритм a:X→Y, способный классифицировать произвольный объект x∈X.
Сформулировать задачу классификации также можно в терминах вероятностной степени. Предполагается, что множество пар «объект, класс» XY является вероятностным пространством с неизвестной вероятностной мерой P. Есть конечная учебная выборка наблюдений
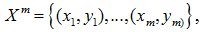
, сгенерированная согласно вероятностной степени P. Необходимо построить алгоритм b:X→Y, способный классифицировать произвольный объект x∈X.
Наиболее распространенным методом классификации является логистическая регрессия. Наиболее распространенная логистическая регрессия – это бинарная (когда выход может принимать только два значения), однако есть более общие модели, рассматривают ситуации полизначимых переменных выхода. Логистическая регрессия обходит проблему не гаусовского распределения и не линейности, используя логит-преобразование зависимой переменной:
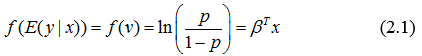
Где Y∈(0,1).
Функцию в таком случае называют логит-преобразованием, а отношение
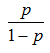
– шансами (с англ. odds).
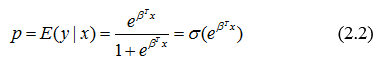
Функцию называют сигмоидой, или логистической функцией. Важной особенностью этой функции является ее область значений: E(σ)=[0:1], – что как никак лучше подходит для оценки вероятности. Таким образом, из предположения:

Что в другой форме имеет вид
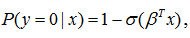
получаем:
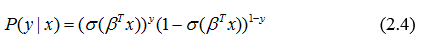
Пусть имеем вектор наблюдений выхода и матрицу значений независимых переменных
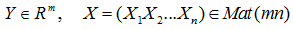
– соответственно. Тогда функция правдоподобия и ее натуральный логарифм будут иметь вид:
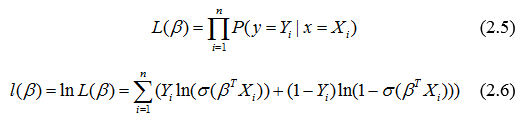
Естественным образом встает задача максимизации этих функций.
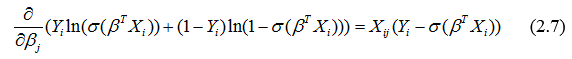
Отсюда градиент логарифмической функции правдоподобия:
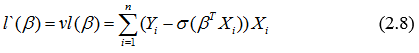
Найдем ее матрицу Гессе:
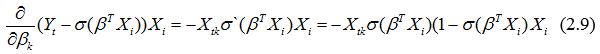
Тогда матрица Гессе будет выглядеть:
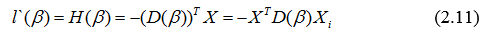
где
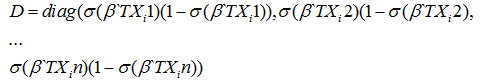
Теперь можно найти оценку вектора β, например, методом Ньютона:
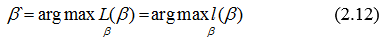
Основная задача логистической регрессии – это корректно спрогнозировать категорию, в которую попадает, переменная выхода. Для построения такой модели можно применять пошаговое построение, когда качество модели оценивается вместе с добавлением или, наоборот, удалением возможных переменных – претендентов. Результат такого процесса — набор регрессоров, имеющих оптимальные свойства, такие как смещение и вариация.
Любой регрессионный подход требует существования тренировочной выборки, то есть исторических наблюдений, что уже так или иначе классифицированы. Однако очень часто возникают случаи, когда исследователь априори не знает ни сами классы, в которые попадают наблюдения, а иногда и даже количество классов. В таких случаях применяют методы кластеризации или классификации без учителя.
Кластерный анализ – задача разбиения заданной выборки объектов (ситуаций) на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
Кластерный анализ — это многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивает объекты в сравнительно однородные группы — кластеры (Q-кластеризация, или Q-техника, собственно кластерный анализ).
Основная цель кластерного анализа — нахождение групп схожих объектов в выборке. Спектр применений кластерного анализа очень широк: его используют в археологии, антропологии, медицине, психологии, химии, биологии, государственном управлении, филологии, маркетинга, социологии и других дисциплинах. Однако универсальность применения привела к появлению большого количества несовместимых терминов, методов и подходов, затрудняющих однозначное использование и непротиворечивую интерпретацию кластерного анализа.
Пусть X – множество объектов, Y – множество номеров (имен, меток) кластеров. Задана функция расстояния между объектами p(x,x`). Есть конечная выборка объектов .
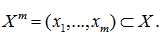
Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике p, а объекты разных кластеров существенно отличались. При этом каждому объекту
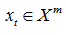
приписывается номер кластера yi.
Алгоритм кластеризации – это функция a:X→Y, которая любому объекту x∈X ставит в соответствие номер кластера y∈Y. Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения некоторого критерия качества кластеризации.
Объединения схожих объектов в группы может быть осуществлено различными способами. Именно для этого этапа существует целый ряд методов:
- K-means;
- C-means;
- графовые алгоритмы кластеризации;
- статистические алгоритмы кластеризации;
- алгоритмы семейства FOREL;
- иерархическая кластеризация;
- нейронная сеть Кохонена;
- ансамбль кластеризаторов;
- EM-алгоритм.
Рассмотрим 2 наиболее популярных из них. Пусть задана выборка наблюдений x=(x1,x2,…,xn), где каждое наблюдение
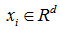
, алгоритм k-средних на то, чтобы разбить наблюдений на k множеств
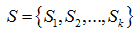
таким образом, чтобы минимизировать вариацию внутри каждого из классов. Формально целевую функцию можно записать следующим образом:
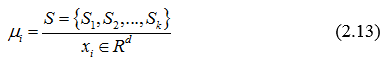
Где μi – математическое ожидание точек в Si. Это эквивалентно минимизации попарной вариации точек одного кластера:

Эквивалентности можно получить из равенства
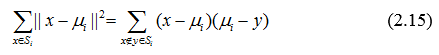
А поскольку общая вариации является константой, то это условие является также эквивалентна максимизации вариации между кластерами.
Список литературы
- Islam, Asadul Khandoker et al. 2010. “Fraud Detection in ERP Systems Using Scenario Matching.” In Security and Privacy — Silver Linings in the Cloud, eds. Kai Rannenberg, Vijay Varadharajan, and Christian Weber. Berlin, Heidelberg: Springer Berlin Heidelberg, 112–23.
- Kundu, Amlan, Shamik Sural, and A K Majumdar. 2006. “Two-Stage Credit Card Fraud Detection Using Sequence Alignment.” In Information Systems Security, eds. Aditya Bagchi and Vijayalakshmi Atluri. Berlin, Heidelberg: Springer Berlin Heidelberg, 260–75.
- Lim, Wee-Yong, Amit Sachan, and Vrizlynn Thing. 2014. “Conditional Weighted Transaction Aggregation for Credit Card Fraud Detection.” In Advances in Digital Forensics X, eds. Gilbert Peterson and Sujeet Shenoi. Berlin, Heidelberg: Springer Berlin Heidelberg, 3–16.
- Wei, Wei et al. 2013. “Effective Detection of Sophisticated Online Banking Fraud on Extremely Imbalanced Data.” World Wide Web 16(4): 449–75. https://doi.org/10.1007/s11280-012-0178-0.
- Kim, Ae Chan, Seongkon Kim, Won Hyung Park, and Dong Hoon Lee. 2014. “Fraud and Financial Crime Detection Model Using Malware Forensics.” Multimedia Tools and Applications 68(2): 479–96. https://doi.org/10.1007/s11042-013-1410-3.
- Carminati, Michele et al. 2014. “BankSealer: An Online Banking Fraud Analysis and Decision Support System.” In ICT Systems Security and Privacy Protection, eds. Nora Cuppens-Boulahia et al. Berlin, Heidelberg: Springer Berlin Heidelberg, 380–94.
- Hand, D J et al. 2008. “Performance Criteria for Plastic Card Fraud Detection Tools.” Journal of the Operational Research Society 59(7): 956–62. https://doi.org/10.1057/palgrave.jors.2602418.
- Molloy, Ian et al. 2017. “Graph Analytics for Real-Time Scoring of Cross-Channel Transactional Fraud.” In Financial Cryptography and Data Security, eds. Jens Grossklags and Bart Preneel. Berlin, Heidelberg: Springer Berlin Heidelberg, 22–40.