
УДК 519.688
DOI 10.24411/2658-3569-2020-10031
РАЗРАБОТКА ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ СО СВЕРТОЧНЫМИ СЛОЯМИ ДЛЯ АНАЛИЗА РЕТРОСПЕКТИВНЫХ ДАННЫХ ИНТЕРНЕТ-КОНТЕНТА
DEVELOPMENT OF ARTIFICIAL NEURAL NETWORKS WITH CONVOLUTIONAL LAYERS FOR ANALYZING RETROSPECTIVE DATA OF INTERNET CONTENT
Рогачев Алексей Фруминович, доктор технических наук, профессор, заведующий кафедрой, Волгоградский государственный аграрный университет, Всероссийский НИИ орошаемого земледелия, г. Волгоград
Мелихова Елена Валентиновна, кандидат технических наук, доцент, доцент кафедры математического моделирования и информатики, Волгоградский государственный аграрный университет, г. Волгоград
Rogachev A.F., rafr@mail.ru
Melikhova E.V., mel-v07@ mail.ru
Аннотация. В статье рассматривается разработка и применение искусственных нейронных сетей (ИНС) для анализа интернет-контента. Анализируется использование ИНС различной архитектуры – полносвязных, сверточных, рекуррентных — для решения задачи анализа ретроспективных данных, преимущественно текстовых. Представлена эволюция построения эмбеддингов, как векторного представления слов в текстовых корпусах целевой информации. Рассмотрены методы предварительного частотного преобразования словарей, а также построения эмбеддингов с помощью ИНС. Приведен пример двумерной проекции тематического эмбеддинга. Представлены направления перспективного использования описанного подхода для решения задач анализа интернет-контента.
Работа выполнена при финансовой поддержке РФФИ и Администрации Волгоградской области по проекту № 19-416-340014 «Создание нейросетевой системы управления программируемым аграрным производством с использованием ретроспективных данных и результатов дистанционного зондирования для засушливых условий Волгоградской области».
Summary. The article deals with the development and application of artificial neural networks (ANN) for the analysis of Internet content. We analyze the use of ANN of various architectures – Dense, Convolutional, and Recurrent — to solve the problem of analyzing retrospective data, mainly text data. The evolution of embedding construction, as a vector representation of words in text corpora of target information, is presented. Methods of preliminary frequency conversion of dictionaries, as well as embeddings using ANN, are considered. An example of a two-dimensional projection of a thematic embedding is given. The directions of prospective use of the described approach for solving problems of Internet content analysis are presented.
Ключевые слова: интернет-контент, анализ, искусственная нейронная сеть (ИНС), архитектура ИНС, ретроспективные данные, эмбеддинг.
Keywords: Internet content, analysis, artificial neural network (ins), ins architecture, retrospective data, embedding.
Введение. Разработка искусственных нейронных сетей (ИНС) и их применение для анализа интернет-контента представляет собой задачу, актуальную для различных отраслей производств, включая аграропромышленный комплекс [1, 3, 4]. Для ее решения используются искусственные нейронные сети (ИНС) различной архитектуры, основанные на скрытых слоях нейронов различного функционального назначения — полносвязных, сверточных, рекуррентных и др. Для эффективного решения задачи анализа ретроспективных данных, преимущественно текстовых, требуется специальная предварительная числовая подготовка и преобразование исходных данных, в частности эмбэддинг, как векторное представление слов в текстовых корпусах целевой информации.
Методы и материалы
Анализ методов ИИ для обработки текстов на естественных языках (NLP — Natural Language Processing) выявил этапы эволюции построения эмбеддингов. Термин «Эмбеддинг» в NLP означает процесс или, чаще, результат процесса преобразования языковой сущности – слова, предложения, параграфа или целого текста в набор чисел – числовой вектор.
Простейшим методом построения эмбэддинга является унитарное кодирование («one-hot encoding») [3], когда эмбеддинги слов получают обычной нумерацией слов в достаточно значимом словаре и присвоение единицы в векторе, размерность которого соответствует количеству слов в выбранном словаре. Отметим, что непосредственное использование корпусов текста не всегда помогает получить практический результат от превращения некоторого текста в кортеж чисел, поскольку на естественном языке текст представляет собой не только набор слов («bag of words”), но и несет некоторую семантику, определяемую их последовательностью.
Известен ряд алгоритмов анализа текстов: латентный семантический анализ, латентное размещение Дирихле и тематические модели Biterm для коротких текстов [3].
Результаты и обсуждения
Любому предложению на естественном языке можно поставить в соответствие кортеж многомерных векторов-эмбеддингов для проведения компьютерного семантического анализа текста. Одной из проблем применения описанных эмбеддингов, является возможное отсутствие в сформированном словаре термина, для которого ищется эмбеддинг. Снизить угрозу появления этой проблемы можно без использования специального словаря, а нумеруя слова в произвольном обширном наборе текстов, например, в БСЭ. Для этих целей формируют специальные наборы текстов, называемые корпусами — отобранные и обработанные по определённым правилам совокупности текстов, используемых в качестве базы для исследования естественного языка.
Эволюционным подходом к обработке текстов явился учёт того, как часто каждое конкретное слово языка (термин) встречается в корпусе и насколько важно его появление в данном тексте. Так возник частотный эмбеддинг, в котором каждому слову в позицию, соответствующую его номеру, ставится в соответствие число — частота слова.
Более полезным является скорректированная оценка значение частоты — обратная частота слов документа, (инверсия частоты), с которой некоторое слово встречается в документах коллекции, позволяющая снизить весомость наиболее часто используемых слов — предлогов, союзов, общих понятий. Значение показателя обратной частоты будет выше, если определённое слово с большой частотой используется в конкретном тексте, но редко — в других документах. Каждое слово wi в обучающей выборке отбрасывается с вероятностью, вычисленной по формуле (1). Значение константы t в (1) рекомендуется принимать равным 10-5.
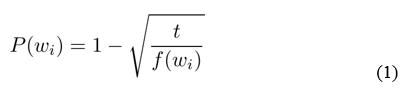
где f(wi) — частота слова wi;
t – эмпирическая константа.
Зависимость (1) позволяет сэмплировать слова, частота которых превышает значение t при сохранении ранжирования частот.
Использование векторов-эмбеддингов скорректированных наборов слов позволяет осуществить автоматический семантический анализ, определяя имеющиеся в корпусе текстов темы, классифицировать тексты по основным темам.
Для повышения эффективности компьютерного анализа с использованием эмбеддингов, Томаш Миколов (Tomas Mikolov, 2013) выдвинул гипотезу локальности, согласно которой «слова, которые встречаются в одинаковых окружениях, имеют близкие значения» [4]. В данном случае близость понимается, как взаимное расположение сочетающиеся слов. Для этого эмбеддинги слов строят в векторном пространстве, размерность которого вне зависимости от объема словаря может составлять порядка 102 … 103. Тогда каждому слову будет соответствовать набор из нескольких сотен чисел, математически удовлетворяющих свойствам векторного пространства. Такие векторы можно складывать, умножать на скаляры, между ними можно определять расстояния, причем такие операции имеют определенный смысл, как действие над словами.
В качестве примера, результат векторного вычисления
Vec(res) = vec («Мадрид») — vec (”Испания») + vec (”Франция») (2)
ближе к vec (”Париж»), чем к любому другому векторному слову [8, 9].
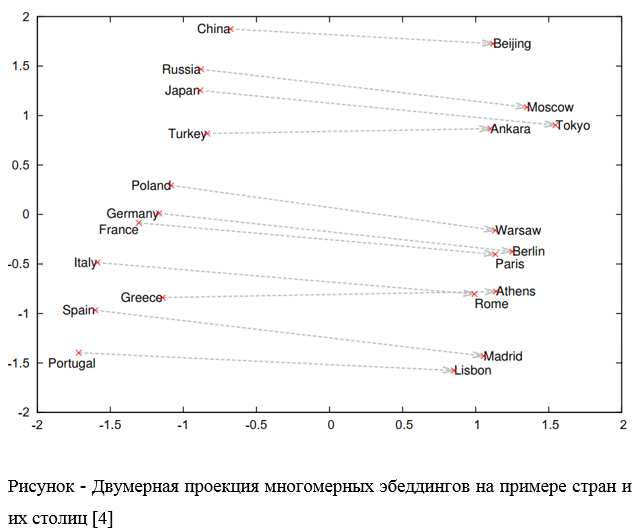
Метод построения таких эмбеддингов, основанный на вероятностной оценке совместного использования сочетания слов посредством ИНС, обучаемых на тематических корпусах текстов, получил название «word2vec». Идея такого подхода явилась основой для получения моделей эмбеддингов не только отдельных слов и предложений, но и целых документов. Так появилась разработанная в Стэнфордском университете модель GloVe, разработанная Facebook модель «fastText», а также, разработанной Google AI Language модели BERT (2018). Модель «doc2vec» отображает в числовой вектор целые текстовые документы [7].
В настоящее время эмбеддинги получают с помощью достаточно сложных моделей ИНС глубокого обучения, обеспечивающих сохранение в элементах таких векторов всё более глубинных отношений естественного языка. В связи с этим, некоторые эксперты характеризуют появление таких эмбеддингов, как новую эру ИИ [5].
Отметим открывающуюся возможность эмбеддингов для синхронного оперирования на различных языках. Если строить векторное пространство эмбеддингов слов и предложений, например на русском и английском, то одинаковым семантическим категориям будут соответствовать аналогичные геометрически подобные эмбеддинги. Тогда перевод тематического текста, например, с английского языка будет сводиться к построению его эмбеддинга с последующим декодированием в терминах того языка, на который требуется перевод. Уже известны «поисковые машины, которые принимают запрос на одном языке и отыскивают информацию на любом языке, используя обратный индекс на основе эмбеддингов» [3].
Перспективным направлением развития ИИ на основе эмбеддингов можно считать достаточно универсальный подход, основанный на гипотезе возможности запрограммировать процесс «мышления» словами в естественной языковой форме [3].
Системы искусственного интеллекта (ИИ) на основе эмбеддингов позволяют не только понимать сущность текстов, сформулированных человеком на естественных языках и подбирать заранее подготовленные на их основе альтернативы, но и предлагать сами варианты решения. В системах ИИ это может осуществляться посредством архитектур с гибридными ИНС, генетическими алгоритмами, деревьев целей и других методов. Такие алгоритмы эффективно работают, если данные представлены в виде числовых векторов-эмбеддингов.
Выводы. Перспективным направлением развития ИИ на основе эмбеддингов можно считать достаточно универсальный подход, основанный на идее, что возможно запрограммировать «мышление» словами, в языковой форме. Кроме того, состояния окружающего мира могут сразу преобразовываться в форму эмбеддингов, исключая словесное формулировки. При этом, аудио- или видеозаписи возможно непосредственно преобразовывать в многомерные векторы-эмбеддинги соответствующей размерности.
Литература
- Гагарин А.Г., Рогачев А.Ф. Применение искусственных нейронных сетей для прогнозирования урожайности на основе анализа кросс-региональных данных // Известия Нижневолжского агроуниверситетского комплекса: Наука и высшее профессиональное образование. 2018. № 2. С. 339-346.
- Крылов В. Что такое эмбеддинги и как они помогают искусственному интеллекту понять мир людей // Наука и жизнь. 2020. № 03. Электронный ресурс] URL: https://www.nkj.ru/open/36052/ (30.03.2020)
- Мелихова Е.В., Мелихов Д.А. Применение беспилотных летательных аппаратов в аграрном производстве // Международный журнал прикладных наук и технологий Integral. 2019. № 3. С. 29.
- Мелихова Е.В., Бородычев В.В., Рогачев А.Ф. Функционально-морфологический анализ и совершенствование технических средств комбинированного орошения // Мелиорация и водное хозяйство. 2018. № 4. С. 30-36.
- Рогачев А.Ф. Системный анализ и прогнозирование временных рядов урожайности на основе автокорреляционных функций и нейросетевых технологий // Известия Нижневолжского агроуниверситетского комплекса: Наука и высшее профессиональное образование. 2018. № 3 (51). С. 309-316.
- Alammar J. The Illustrated BERT, ELMo, and Co. (How NLP Cracked Transfer Learning) [Электронный ресурс] URL: http://jalammar.github.io/illustrated-bert/ (30.03.2020).
- Word2vec [Электронный ресурс] URL: https://code.google.com/archive/p/word2vec/
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. ICLR Workshop, 2013.
- Tomas Mikolov, Wen-tau Yih and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL HLT, 2013.
- Mikolov T., Sutskever I., Chen K. Distributed Representations of Words and Phrases and their Compositionality arXiv:1310.4546 [cs.CL] Электронный ресурс] URL: https://arxiv.org/abs/1310.4546v1 (30.03.2020).