
УДК 519.23
DOI 10.24411/2658-3569-2020-10119
ОБ ОДНОЙ КОЛИЧЕСТВЕННОЙ ХАРАКТЕРИСТИКЕ НАСЕЛЕНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
ONE QUANTITATIVE CHARACTERISTIC OF THE RUSSIAN FEDERATION POPULATION
Половодова Елизавета Викторовна, Пермский национальный исследовательский политехнический университет
Научный руководитель: Севодин Михаил Алексеевич, к.ф.-м.н., доцент, Пермский национальный исследовательский политехнический университет
Аннотация. В работе исследуется способ построения обобщенного показателя на примере общей численности населения в РФ. Рассматривается метод оценки Томсона как инструмент для нахождения латентного фактора. С помощью критерия тетрад (триад) Спирмена рассматривается возможность представления общности генеральными факторами, определения группы показателей, наиболее полно характеризующих общую численность населения в РФ. Далее строится сводный индекс, с помощью которого представляется возможным в дальнейшем оценивать группу факторов, характеризующих один из количественных показателей населения РФ. Затем высчитывается нагрузка обобщенного показателя на частный показатель.
Summary. The article is devoted to the study of constructing a generalized indicator on the example of the Russian Federation total population. The Thomson estimation method is considered as a tool for finding the latent factor. Using Spearman’s tetrad (triad) criterion, we consider the possibility of representing generality by General factors, determining the group of indicators that most fully characterize the Russian Federation total population. Then a composite index is constructed, with which it is possible to evaluate the group of factors that characterize one of the quantitative indicators of the Russian Federation population. Then the generalized indicator’s load on the particular indicator is calculated.
Ключевые слова: обобщенный показатель, тетрады, триады, факторы.
Keywords: generalized indicator, tetrads, triads, factors.
Введение
В процессе экономической деятельности страны в связи с повышением ее эффективности большое значение имеет задача снижения затрат на то или иное мероприятие, связанное с вычислением описательных характеристик страны. Очевидно, что при большом количестве этих показателей требуется некий сводный индекс, который, распределив значимость различных факторов, позволит оценивать группу показателей для расчета численности населения РФ.
В данной статье в качестве инструмента для построения общего индекса рассматривается метод Томсона. Использование этого метода в указанном направлении связано с возможностью описания нескольких показателей одним генеральным фактором. В работе данный момент исследований осуществляется с помощью метода тетрад. Для практической иллюстрации обсуждаемых проблем приводится конкретный пример. Объект данного исследования — показатели, которые могут характеризовать численность населения. Предполагается, что существует зависимость между численностью населения и такими показателями, как рост населения, коэффициент рождаемости, ожидаемая продолжительность жизни при рождении, коэффициент младенческой смертности, коэффициент рождаемости среди подростков.
Задача заключается в том, чтобы построить одномерный индекс, определяющий численность населения в РФ.
Построение показателя
Опишем предлагаемую схему построения сводного показателя. Первым этапом является доказательство того, что мы можем описать несколько показателей одним общим фактором. Это доказательство проводим проверкой выполнения критерия тетрад. Следующим шагом после определения данных факторов будет их последовательное сведение в единый показатель методом Томсона.
Метод Томсона решает задачу определения нагрузок показателей на общий фактор. Опишем данный метод.
Основное уравнение факторного анализа представлено следующей формулой:
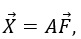
где А – матрица факторных нагрузок,
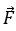
– вектор общих факторов,

– p-мерный вектор показателей.
Метод Томсона рассматривает эту формулу «наоборот», то есть как регрессию зависимых переменных f(1),…,f(p) по аргументам x(1),…,x(p) [1]. Таким образом, коэффициенты cij из уравнения
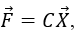
где C – матрица коэффициентов cij, в соответствии с МНК можно найти из условия
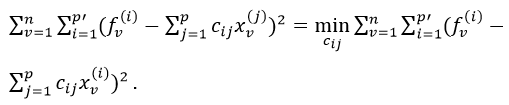
Отсутствие значений зависимых переменных f(j) компенсируем знанием их ковариаций:
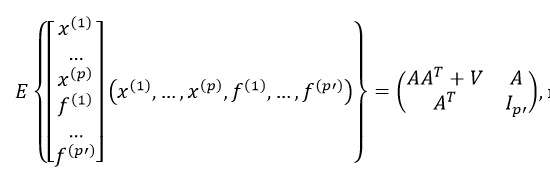
V – матрица остаточных дисперсий.
В итоге, используя МНК, получаем
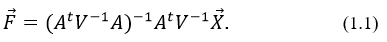
Применение метода Томсона
Для расчетов взята информация о численности населения в Российской Федерации за период 1985-2018 гг.
Выборка, использованная для расчетов, состоит из временного ряда с продолжительностью в 34 года (1985-2018) и 5 признаков:
- X(1) Рост населения (в % в год);
- X(2) Коэффициент рождаемости, общий (на одну женщину);
- X(3) Ожидаемая продолжительность жизни при рождении, общая (в годах);
- X(4) Коэффициент младенческой смертности (на 1000 живорожденных);
- X(5) Коэффициент рождаемости среди подростков (количество рождений на 1000 женщин в возрасте от 15 до 19 лет)
Прежде чем проводить расчеты, нужно проверить исходные данные на критерий Спирмена.
Из критерия триад Спирмена известно, что 2 и 3 показателя можно описать одним генеральным фактором. Однако для большего числа показателей (в нашем случае их 5) необходимо выполнение следующих условий.
Рассмотрим матрицу корреляции при n=1 и m=5:
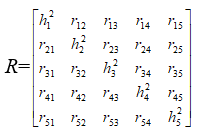
Ранг этой матрицы равен единице, если все миноры второго порядка равны нулю.
Выбрав миноры, в которые входит лишь по одному значению общности, выпишем ряд уравнений относительно всех общностей.
Например, h12 может быть вычислен из любого из следующих четырех уравнений:
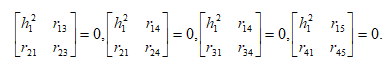
или
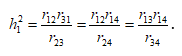
Исключив h12, получим известный критерий тетрад Спирмена .
Таким образом, мы определили условия, которым должны удовлетворять исходные данные для того, чтобы их можно было описать одним генеральным фактором.
Однако возможна такая ситуация, что несколько переменных невозможно будет описать одним латентным фактором. В таком случае используется кластеризация, т.е. разбиение исходных данных на группы. Если в кластере не больше трех показателей, то их можно описать одним генеральным фактором, в противном случае снова проверяется критерий тетрад. Если критерий опять не выполняется, то разбиваем группы на кластеры с большей точностью. Таким образом, у нас получается набор из N групп. Соответственно, сколько будет групп, столько и латентных факторов мы получим.
Проведя необходимые расчеты, нам стало видно, что в случае с пятью характерными факторами критерий Спирмена не выполняется. Значения представлены в таблице 1:
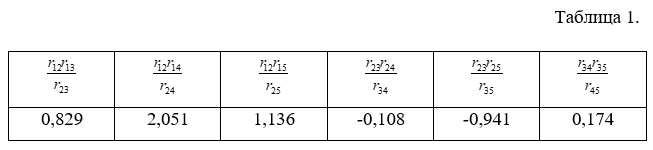
Перед нами встает задача о снижении размерности. В итоге мы можем получить большую наглядность данных, отсюда и лаконизм и простоту построения зависимостей и, конечно же, резкое снижение объемов хранимой информации.
Решим вопрос о возможности исключения факторных признаков X1,X2,X3,X4,X5.
Найдем коэффициенты парной корреляции между всеми пятью признаками. Получили, что наибольшие – между признаками X1и X2; X4 и,X5:
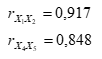
Для решения вопроса, какие из факторов следует исключить из модели множественной линейной корреляции, вычислим коэффициенты парной корреляции:
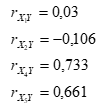
Заметим, что между признаками X2и Yсвязь сильнее, чем между X1 и Y.
Аналогично, между признаками X4 и Y связь сильнее, чем между X5 и Y.
Поэтому из модели множественной линейной корреляции исключаем фактор X1 и X5. Тогда в модель будут включены факторы X2, X3, X4.
Проведем вновь проверку критерия тетрад Спирмена уже с тремя характерными признаками. Напомним, что для того, чтобы n параметров выражались через один генеральный и n характерных факторов, необходимо и достаточно, чтобы все тетрады (триады) равнялись нулю.
Критерий Спирмена для трех факторов выполняется.
Идея применения факторного анализа для определения весовых коэффициентов аддитивной функции полезности основана на том, чтобы рассматривать функцию полезности как некий обобщенный фактор. В этом случае, частными показателями являются частные функции полезности.
Итак, запишем основное предположение факторного анализа:
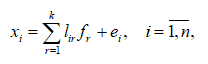
В случае одного фактора (k=1) оно будет иметь вид:

где xi – частный показатель; f – обобщенный показатель; li – нагрузка (вес) обобщенного показателя f на частный показатель xi; ei – остаток (характерный показатель), определяющий ту часть показателя xi, изменение которой вызвано действием случайной величины.
Вычисляя li, будем предполагать, что остатки в (2.1) равны нулю.
Фактор f в данном случае является генеральным, т.е. имеет нагрузки всех переменных.
Имеем формулу для вычисления факторных нагрузок:
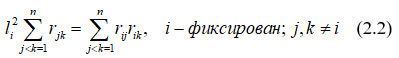
Символ
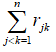
означает, что суммирование ведется по индексам j и k, которые пробегают значения 1,…,n, причем в любом из членов j меньше k. В симметрической корреляционной матрице – это сумма всех элементов матрицы выше (или ниже) главной диагонали.
Формулу (2.2) можно переписать в виде:
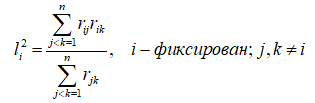
В данном выражении знаменатель есть сумма всех элементов корреляционной матрицы, за исключением коэффициентов корреляции рассматриваемого параметра i, а числитель – сумма парных произведений коэффициентов корреляции параметра i с каждым из остальных параметров.
Для машинных вычислений более удобным является следующий вид:
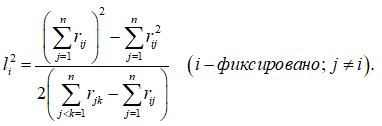
Проведя необходимые вычисления, получили:
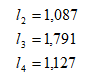
Таким образом, тремя показателями, такими как общий коэффициент рождаемости; ожидаемая продолжительность жизни при рождении; коэффициент младенческой смертности, представилось возможным описать количественную характеристику РФ, не воспользовавшись информацией о переписи населения. Этот факт в значительной мере позволяет сократить государственные расходы. Получили, что ожидаемая продолжительность жизни в большей мере позволяет строить прогнозы относительно численности населения.
Заключение
В работе был предложен подход совместного использования регрессионного анализа и критерия Спирмена для определения группы показателей, наиболее полно характеризующих общую численность населения в РФ. Первое позволило нам определить количество предполагаемых факторов, второе — определить их. Также положительным эффектом являлось то, что мы смогли сказать, с какой силой (весом) та или иная характеристика повлияла на общий фактор.
Литература
- Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. М.: Издательское объединение «ЮНИТИ», 1998 – 1006 с.
- Дронов С.В. Многомерный статистический анализ. : Учебное пособие. Барнаул: Изд-во Алт. гос. ун-та, 2003 – 213 с.
- Единая межведомственная информационно-статистическая система [Электронный ресурс]. Режим доступа: http://www.fedstat.ru/indicator/data.do.
- Иберла К. Факторный анализ / Пер. с нем. В.М. Ивановой; Предисл. А.М. Дуброва. – М.: Статистика, 1980 – 398 с., ил. – (Математико-статистические методы за рубежом).
- Харман Г. Современный факторный анализ – М.: Статистика, 1972 – 243 с.
- Лоули Д., Максвелл А. Факторный анализ как статистический метод 1967 – 102 с.