
УДК 004.8
МОДЕЛИРОВАНИЕ ТРЕБОВАНИЙ К СИСТЕМАМ МАШИННОГО ОБУЧЕНИЯ
REQUIREMENTS MODELING FOR MACHINE LEARNING SYSTEMS
Ерискин Виталий Владимирович, Московский государственный технический университет им. Н. Э. Баумана, г. Москва
Eriskin Vitaly Vladimirovich, The Moscow State Technical University, Moscow, e-mail: eriskinv@gmail.com
Аннотация. Применение систем, основанных на методах машинного обучения, становится все более и более распространенным. Однако, требования к таким системам зачастую трудно выразить в полном объеме, поэтому могут возникать конфликты, которые трудно обнаружить, и как следствие такие системы не могут полностью удовлетворить потребности пользователей в реальной прикладной среде. Для систем машинного обучения (MLS), используемых в реальных сценариях, доверие пользователей обычно зависит от удовлетворения требований, включая нефункциональные требования, такие как интерпретируемость и объективность. Для решения вышеупомянутых проблем в данной статье представлена концептуальная модель требований к MLS, метамодель конвейера процесса MLS, а также процесс принятия решения о выборе обучающих наборов данных и выборе алгоритмов. Цель работы состоит в том, чтобы стандартизировать разработку и оценку требований для машинного обучения, используемых в реальных сценариях.
Summary. The use of systems based on machine learning methods is becoming more and more common. However, the requirements for such systems are often difficult to express in full, therefore conflicts may arise that are difficult to detect, the systems themselves cannot fully meet the needs of users in a real application environment. For machine learning systems (MLS) used in real-world scenarios, user trust usually depends on satisfying requirements, including non-functional requirements such as interpretability and objectivity. To address the aforementioned issues, this article presents a conceptual model of MLS requirements, a metamodel of the MLS process pipeline, and a decision-making process for choosing training datasets and choosing algorithms. The goal of the work is to standardize development and evaluation of machine learning requirements used in real-world scenarios.
Ключевые слова: машинное обучение, моделирование требований к программному обеспечению, нефункциональные требования к программному обеспечению, системы машинного обучения.
Keywords: machine learning, software requirements modeling, non-functional software requirements ,machine learning systems.
1 Введение
Машинное обучение (Machine learning, ML) описывает вычислительную модель, которая использует алгоритмы для «обучения» на огромных объемах данных. ML с успехом решает некоторые проблемы, которые трудно решить с помощью традиционных программных систем, например, распознавание изображений, медицинская диагностика, предсказание цен на рыночные активы, и др. [3]. В отличие от какого-либо конкретного алгоритма или модели машинного обучения, система машинного обучения в практических приложениях [1] (Machine Learning Sytems, MLS) относится к полным системам, состоящим: из одной или нескольких моделей машинного обучения; данных, используемых для обучения модели; интерфейсов и документов для взаимодействия пользователя с моделью. Традиционные программные системы обычно используют явные правила взаимодействия человека с компьютером для управления поведением системы, в то время как MLS больше полагаются на характеристики данных и неявные модели принятия решений. Из-за сложных и изменчивых атрибутов данных, трудностей для измерения и плохой интерпретируемости традиционных моделей машинного обучения MLS ставит новые вызовы перед проектированием требований к таким системам.
Во-первых, традиционные требования к программной системе редко предъявляют прямые требования к качеству данных или алгоритмов, которые не циркулируют в системе, в то время как требования MLS могут подразумевать требования к качеству данных для обучения и алгоритмом машинного обучения, например, такие требования как объективность данных, или ограничение на данные с несбалансированным распределением меток для обучения модели. Во-вторых, процесс обучения модели обычно занимает много времени, и алгоритм обучения должен быть четко отлажен. Сложность требований MLS высока, а неполнота и неоднозначность требований MLS может негативно повлияет на последующую реализацию.
По сравнению с традиционными программными системами, если в процессе разработки MLS происходит доработка из-за проблем с неточными первоначальными требованиями, это может приводить к существенным потерям ресурсов и неопределенности. Таким образом, четкое и полное определение требований MLS помогает определить функциональные и нефункциональные требования заинтересованных сторон на ранних этапах разработки программного обеспечения, и как можно раньше определить обучающие данные и алгоритмы, которые соответствуют этим требованиям.
Соответствие поведения и результата работы MLS ожиданиям заинтересованных лиц может быть отражено степенью удовлетворения MLS функциональным и нефункциональным требованиям. Однако по сравнению с традиционными программными системами нефункциональные требования (NFR) к MLS более сложны, и зачастую их трудно выразить полностью, по следующим основным причинам:
1) NFR MLS часто имеет различные характеристики для одного и того же поля. Например, в законодательстве некоторых стран есть гендерные ограничения (запрет на некоторые профессии, в зависимости от гендерной принадлежности), при этом эти ограничения могут распространяться на одну отрасль и не действовать в другой, хотя с точки зрения MLS это одна и та же характеристика данных — пол. Или другие примеры подобного рода — это механизмы защиты личной информации, защита конфиденциальности, в разных странах или отраслях экономики одной страны эти стандарты могут быть разные.
2) NFR MLS включает в себя не только нормальное распределение обучающих данных, но также и объективность, интерпретируемость, безопасность, защиту конфиденциальности и т. д. Различные NFR могут зависеть от различных характеристик данных или алгоритмов в конкретной реализации. Например, объективность MLS в основном зависит от обучения. Защита конфиденциальности в основном зависят от методов шифрования данных, а интерпретируемость в основном зависит от реализации конкретных алгоритмов.
3) Недавние исследования показали [4], что всегда существует определенный компромисс между различными NFR MLS. Например, если безопасность будет улучшена, это определенно повлияет на эффективность, а защита конфиденциальности и объективность не могут быть оптимизированы одновременно.
Таким образом, при моделировании систем MLS существует необходимость в методологии описания использования существующих знаний в предметной области для их обработки, а также эффективного управления последующим отбором данных и разработкой алгоритмов. В этом исследовании предлагается модель для проектирования и выбора решений при проектировании MLS. Сначала вводится целевая модель MLS, которая описывает взаимосвязь между целью и процессом машинного обучения, а затем определяется технология выбора для принятия решений, которая использует цель и NFR, необходимые для оценки конкретных требований к обучающим данным и алгоритмам, чтобы получить лучшее решение в данной конкретной ситуации. Метод анализа и проектирования MLS, предложенный в данной статье поможет эффективно описать и проанализировать нефункциональные требования к характеристикам системы машинного обучения, а также рекомендовать подходящие обучающие данные и алгоритмы машинного обучения.
Можно выделить 2 существенных аспекта предложенного метода:
1) Предлагается концептуальная модель требований MLS. За счет нефункциональных требований к MLS, набора обучающих данных, каталога алгоритмов и структур признаков (Meta-Feature) и их сопоставлений с требованиями пользователей модель преобразуются в решения, которые можно использовать.
2) Предлагается метамодель процесса конвейерного машинного обучения. В соответствии с обучающими данными, извлеченными на предыдущем шаге, и требованиями NFR к алгоритму, используется функция полезности для вычисления количественной оценки обучающих данных и метода выбора алгоритма, и таким образом рекомендуется наиболее эффективная модель машинного обучения, отвечающая потребностям заказчика.
2 Предварительная подготовка
Объем исследований в рассматриваемой области относительно невелик, среди которых, несомненно, следует выделить два наиболее известных стандарта по методологии интеллектуального анализа данных — KDD и CRISP-DM, которые предложили две различные эталонные модели процесса создания MLS. Однако в этих стандартах отсутствует подробный анализ конкретных шагов и не затрагиваются обучающие наборы данных и вопросы выбора алгоритма. В литературе [7] указано, что проблема анализа требований наиболее сложная деятельность при разработке MLS. В обычной программной разработке эта деятельность включает анализ требований и спецификацию на начальном этапе и приемочный контроль на заключительном этапе. При проектировании MLS существующие процедуры могут быть неприменимы из-за невозможности заранее оценить или гарантировать достижимую точность. В литературе [8] указывается на узкие места и возможные направления исследований в области нефункциональных требований MLS, а также говорится, что текущие работы описывают только отдельные специфические факторы NFR (например, конфиденциальность и время обработки), а в целом процесс анализа NFR при планировании MLS не формализован. Это одна из проблем, которую пытается решить данная работа.
Хотя существуют различные варианты задач машинного обучения, существующие методы и инструменты анализа требований часто предполагают, что весь процесс машинного обучения представляет собой единую функцию со схожими характеристиками, и, таким образом, создают множество различных представлений о процессе машинного обучения. Это еще больше усложняет описание требований MLS и выбор методов реализации. В то же время методы обработки, ориентированные на данные, часто медленнее и требуют трудоемких задач (таких как маркировка данных, обучение модели), чтобы справиться с изменяющимися характеристиками объектов машинного обучения. Традиционные фреймворки разработки требований используют общие функции для различных объектов машинного обучения и описания требований MLS. Однако общие функции не подходят для создания изменяющихся и многократно используемых сервисных компонентов для объектов машинного обучения. Следовательно, определение характеристик динамического изменения для комбинации различных компонентов в процессе машинного обучения, таких как предварительная обработка данных, обучение модели и развертывание модели, имеет решающее значение для описания требований MLS и его последующей реализации.
Таким образом, в настоящее время отсутствуют комплексные методы детального моделирования требований и принятия решений на протяжении всего жизненного цикла MLS.
В этой статье предлагается общий метод моделирования требований MLS и выбора решений, который объединяет функциональные требования, ориентированные на машинное обучение, и NFR в метамодель конвейера процесса машинного обучения, генерирует изменяющиеся характеристики и реализует динамическую комбинацию выбора данных и выбора алгоритма. Предложенный метод включает:
- концептуальная модель требований MLS, которая определяет требования и ограничения MLS, включая процедуры проверки, основанные на концепции ограничений, и модель согласованного описания;
- основанную на CRISP-DM [6] расширенную модель конвейера процесса машинного обучения, эта модель определяет комбинацию компонентов процесса машинного обучения, связанных с описанием требований декларативной модели.
3 Концепции, относящиеся к системным требованиям машинного обучения
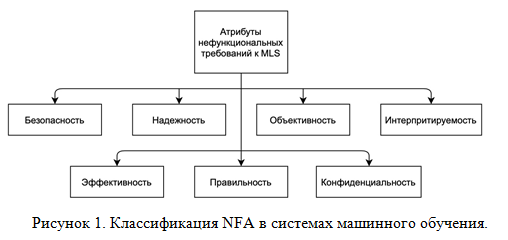
Перед описанием конкретные методов, введем необходимые понятия и определения. Традиционно, нефункциональный атрибут (NFA) MLS обычно относится к таким показателям, как правильность и эффективность, которые можно использовать для описания NFR MLS. С постоянным расширением сценариев приложений машинного обучения и более тесной интеграцией с реальными проблемами, NFA, такие как безопасность, интерпретируемость и объективность, постепенно стали частыми объектами научных исследований, но признанная полная структура NFA пока не сформирована. На рисунке 1 показана классификации NFA в системах машинного обучения.
Определение 2 (проблема требований MLS). Учитывая набор знаний предметной области K, набор задач T, функциональный целевой набор G, не функциональный целевой набор S, найти все возможные решения MLS для удовлетворения проблемы требований и использовать функцию полезности (UF) для оценки возможных решений для определения рекомендуемого решения.
Поскольку описание решения MLS обычно более сложное, оно включает не только модель процесса, но и варианты принятия решений в процессе. Поэтому в этой статье сначала описывается процесс через метамодель процесса конвейера машинного обучения, а затем вычисляются необходимые параметры решения в метамодели с помощью различных функций полезности.
4 Методология
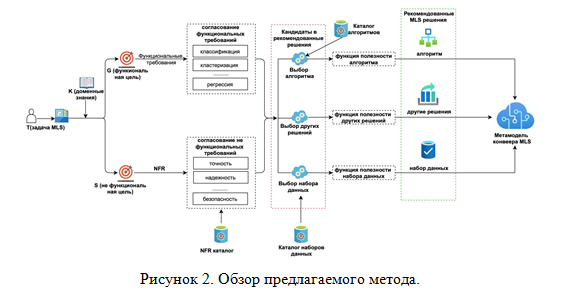
Большинство современных моделей анализа требований основаны на традиционных программных процессах. В этом исследовании предлагается метод моделирования требований MLS и решения проблемы принятия решений, возникающие в процессе разработки программного обеспечения MLS, общий обзор метода показан на рисунке 2. Во-первых, нужно определить задачу MLS, разложить задачу руководствуясь знаниями предметной области и разделить ее на функциональные цели и нефункциональные цели. Процесс выбора соответствия функций определяет тип алгоритма машинного обучения (например, классификация, кластеризация, регрессия и т. д.) в соответствии с функциональными требованиями, запрошенными пользователем. Процесс нефункционального сопоставления определяет набор нефункциональных требований (таких как объективность, точность, интерпретируемость и т. д.) на основе нефункциональных целей пользователя. Во-вторых, в соответствии с функциональными и нефункциональными требованиями, требования к характеристикам обучающих данных и требования к алгоритмам, извлекается соответствующий набор обучающих данных из каталога наборов данных в соответствии с требованиями к характеристикам данных и функцией полезности набора данных. В соответствии с требованиями алгоритма и функцией полезности алгоритма выбирается подходящий алгоритм машинного обучения из каталога алгоритмов. Затем набор обучающих данных и результаты выбора алгоритма вводятся в метамодель конвейера, и разработчик алгоритмов может выполнить программирование, отладку, генерацию модели и тестирование в соответствии с конкретизированной моделью процесса. Наконец, модель развертывается, и пользователь проверяет степень соответствия требованиям. Определение функции полезности набора данных, используемого в данной статье, выглядит следующим образом.
Характеристики набора данных D могут быть выражены как вектор DF=(DF1,…,DFn), где n — общее количество NFR, используемых в системе, а вектор NFR данных DNFRF = (DNFRF1,…,DNFRFn).
WD = (W1, …, Wn), оценочный вектор DF на DNFRF scoreFD = (scoreF1,…,scoreFn), функция полезности набора данных D может быть выражена как:
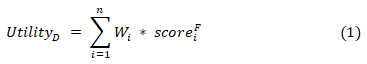

5 Метамодель конвейера процесса машинного обучения
Метамодель конвейера процесса обучения показана на рисунке 3, а точки принятия решения обозначены красным.
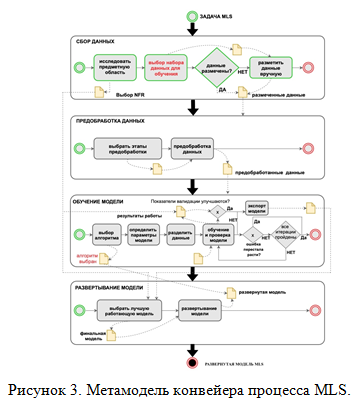
Рассмотрим каждый из этапов, представленных в метамодели конвейера процесса MLS. Сначала следует выбрать набор обучающих данных в соответствии с NFR требованиями пользователя к данным и одновременно определить тип и количество источников данных. Затем соберите данные для каждого источника данных и сохраните их во временной базе данных. Выполните соответствующую предварительную обработку; затем обучающий слой модели выполняет комбинированный анализ на основе показателей и весов оценки NFR, в сочетании с алгоритмом NFR, и выбирает соответствующий алгоритм машинного обучения для каждого конвейера машинного обучения и использует набор обучающих данных для обучения, чтобы создать модель машинного обучения. И наконец, уровень развертывания модели суммирует выходные данные конвейера машинного обучения, использует модель машинного обучения для анализа и прогнозирования данных, предоставленных источником данных, и предоставляет результаты анализа конечному пользователю.
6 Модель описания требований и проверка согласованности
6.1 Модель описания требований MLS
Модель описания требований — это модель, не имеющая ничего общего с данными и алгоритмами, позволяющая пользователям определять набор требований, формирующих MLS. Требования определяют функциональную цель G, которую должна достичь MLS. Набор нефункциональных целей S — это способ измерения или оценки цели, и G — индикатор состояния, который измеряет, достигнута ли цель. Например, пользователи могут выбрать эмоциональное предсказание в качестве функциональной цели G, степень точности предсказания в качестве нефункционального атрибута цели измерения и «степень точности предсказания не менее 90%» в качестве нефункциональной цели S для MLS. Определение модели описания требований следующее:
RDM: = (ai, ω), каждое ai ∈ A,
где A — это набор понятий, требуемых в области MLS,
ω — набор независимых требований,
ωi = {ri, Ci, pri},
где ri – это дополнительное требование, которое может быть выражено иерархически,
Ci = {c1, …, cn} — это набор ограничений для r в процессе анализа,
pri — приоритет ωi.
Например: ωi = {k-Nearest Neighbor, {k> 10}, 1} устанавливает ограничение на параметр k, требуемый алгоритмом k-NN (то есть k> 10), и назначает наибольший приоритет (то есть, pri = 1).
Процесс подготовки данных определяет все действия, направленные на подготовку данных для MLS. Например, описывает, как выполнить уменьшение размерности, или определяет, как использовать методы десенсибилизации данных (такие как алгоритмы асимметричного шифрования) для обеспечения конфиденциальности владельцев данных.
Данные определяют способ представления указанных данных и выбор представления для каждого анализируемого процесса. Например, вы можете определить модели данных (такие как база данных документов MongoDB, графовая база данных Neo4j) и методы хранения (такие как облачное хранилище, сегментирование и т. д.).
Предварительная обработка данных определяет метод, используемый для извлечения, очистки и обработки данных. Например, вы можете определить тип обработки (например, в реальном времени или пакетная обработка) и ожидаемое время ожидания.
Модель обучения определяет тип машинного обучения. Например, вы можете определить ожидаемые результаты (например, описание, пояснение, прогноз) и методы обучения (например, обучение с учителем, обучение без учителя, обучение с подкреплением и т. д.).
Развертывание модели определяет параметры среды развертывания системы. Например, параметры графического процессора, требования к памяти и емкости хранилища и т. д.
Режим представления результатов определяет, как организовать результаты анализа для отображения и абстрактного представления отчета. Например, вы можете определить тип отображения данных (например, облако слов, временная шкала и т. д.).
Описание требований MLS осуществляется в формате JSON для обеспечения общей семантики и взаимодействия между различными этапами.
6.2 Проверка согласованности требований
Описания ограничений используются для обогащения модели описания требований, унифицированный механизм предварительной обработки данных может не подходить для нескольких типов данных, которые связывают несовместимые или взаимно ограничивающие цели и функции. atribute, представляет собой атрибут модели процесса / развертывания, value — это значение (или массив значений) данного атрибута.
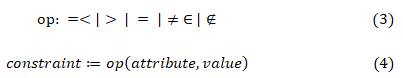
Пусть ωa и ωb — два описания требования, а приоритет требования ωa больше, чем ωb. Затем вводится формальная концепция ограничений для обнаружения несогласованных описаний требований и управления процессом проверки модели описания требований. В частности, ограничение определяется как отношение { ωa , ωb } ∈ , где является набором всех ограничений.
Процесс обнаружения ограничений ζ: → R, принимает ограничения в {ωa , ωb} ∈ в качестве входных данных и возвращает правило r ∈ R, которое должно выполняться на ωb, в качестве выходных данных, чтобы сгенерировать согласованную модель описания. При этом ωa является описанием требований с более высоким приоритетом, и в соответствии с правилом r несоответствие между ωa и ωb может быть разрешено путем изменения диапазона ωb. Сначала выставляются приоритеты требований к MLS, а затем разрешаются конфликты ограничений. Распределение приоритетов позволяет избегать конфликтов и противоречий при моделировании MLS. Ограничения обеспечивают поддержку пользователей с различными возможностями в спецификациях низкоуровневых настроек, и эти настройки будут применяться к параметрам системы в процессе выполнения. Ограничения определяются как структуры объектных данных, то есть набор атрибутов.
Следует отметить, что различные уровни абстракции ведут к различным точкам выполнения. Когда ограничение определено как часть описания требования, то есть ωi = {ri, Ci, pri}, ограничения будут реализованы и согласованы на уровне описания требования.
7 Выводы
Существует определенный пробел в понимании требований, предъявляемых к MLS, что может привести к учету не всех необходимых требований, и вызвать в дальнейшем внутренние конфликты в системе. Кроме того, при разработке систем машинного обучения обычно используется восходящий, ориентированный на технологии подход, а рабочий процесс его выполнения и соответствующие вычисления обычно скрыты от конечных пользователей, разработчиков и архитекторов, что создает скрытые опасности для качества системы. Практика концептуальной модели и метамодели оказалась важным способом улучшения качества систем MLS. В этом документе предлагается метод моделирования требований и выбора решения для систем машинного обучения, включая концептуальную модель требований MLS и метамодель процесса конвейера машинного обучения, которая поддерживает анализ компонентов процесса машинного обучения (таких как наборы данных и алгоритмы обучения) с помощью декомпозиция требований. Смысл точного выбора заключается в концептуальном моделировании и обосновании требований MLS на ранней стадии разработки требований, а также в определении стратегии реализации для удовлетворения всех функциональных и нефункциональных требований, предъявляемых к MLS.
Литература
- Луис Педро Коэльо, Вилли Ричарт. Построение систем машинного обучения на языке Python. // М.: ДМК Пресс. 2016. – 302 с.
- Алпайдин Э. Машинное обучение: новый искусственный интеллект. // М. : Издательская группа «Точка», Альпина паблишер. 2017. — 208 с.
- ALPAYDIN E. Introduction to machine learning. // MIT Pres. – 579 p.
- Hapke H., Nelson C. Building Machine Learning Pipelines. // O’Reilly. 2020. – 366 p.
- Jeremy Watt, Reza Borhani, Aggelos Katsaggelos. Machine Learning Refined. // Cambridge University Press. 2020. – 544 p.
- CHAPMAN P.,CLINTON J.,KERBER R. CRISP-DM 1.0 Step-by-step Data Mining Guide // htps://www.the-modeling-agency.com/crisp-dm .pdf
- ISHIKAWA F.,YOSHIOKA N. How do engineers perceive difficulties in engineering of machine-learning systems? // ACM Joint 7th International Workshop on Conducting Empirical Studies in Industry (CESI) and 6th International Workshop on Software Engineering Research and Industrial Practice (SER&IP). 2019.
- HORKOFF J. Non-functional requirements for machine learning: Challenges and new directions. // IEEE 27th International Requirements Engineering Conference (RE). IEEE 2019.
- TOMSETT R.,BRAINES D.,HARBORNE D. Interpretable to whom? A role-based model for analyzing interpretable machine learning systems //. arXiv:1806.07552.
Literature
- Luis Pedro Coelho, Willie Richart. Building machine learning systems in Python. // M.: DMK Press. 2016. — 302 p.
- Alpaidin E. Machine learning: a new artificial intelligence. // M.: Publishing group «Tochka», Alpina publisher. 2017. — 208 p.
- ALPAYDIN E. Introduction to machine learning. // MIT Pres. 2020. — 579 p.
- Hapke H., Nelson C. Building Machine Learning Pipelines. // O’Reilly. 2020. — 366 p.
- Jeremy Watt, Reza Borhani, Aggelos Katsaggelos. Machine Learning Refined. // Cambridge University Press. 2020. — 544 p.
- CHAPMAN P. , CLINTON J. , KERBER R. CRISP-DM 1.0 Step-by-step Data Mining Guide // htps: //www.the-modeling-agency.com/crisp-dm .pdf
- ISHIKAWA F. , YOSHIOKA N. How do engineers perceive difficulties in engineering of machine-learning systems? // ACM Joint 7th International Workshop on Conducting Empirical Studies in Industry (CESI) and 6th International Workshop on Software Engineering Research and Industrial Practice (SER & IP). 2019.
- HORKOFF J. Non-functional requirements for machine learning: Challenges and new directions. // IEEE 27th International Requirements Engineering Conference (RE). IEEE. 2019.
- TOMSETT R., BRAINES D., HARBORNE D. Interpretable to whom? A role-based model for analyzing interpretable machine learning systems //. arXiv: 1806.07552. 2018.